Towards Quantifying and Reducing Language Mismatch Effects in Cross-Lingual Speech Anti-Spoofing
IEEE Spoken Language Technology Workshop (SLT) 2024, Macau, China
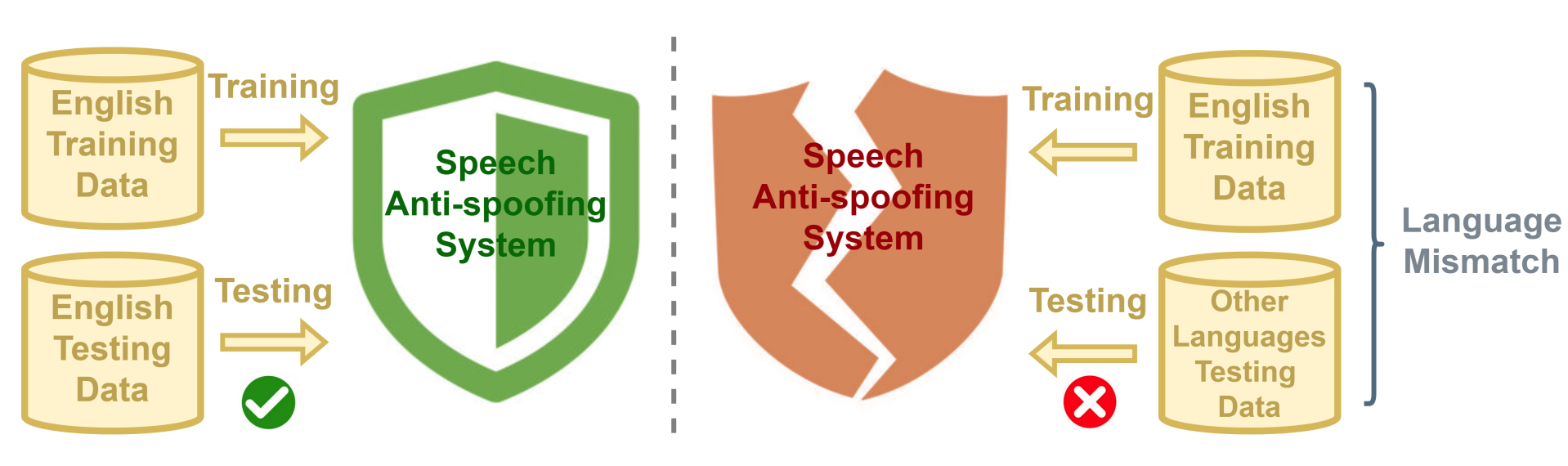
Problem Statement
- Language mismatch negatively impacts the performance of speech anti-spoofing systems.
- Existing anti-spoofing datasets are predominantly in English. Acquiring multilingual datasets, especially for low-resource languages, is costly and challenging.
- There is a need to quantify the extent to which language mismatch affects anti-spoofing systems.
Take Home Message
- It is estimated that language mismatch effect can cause a relative performance reduction of over 15%. This highlights the need for models that are robust across different languages.
- Data augmentation using TTS with diverse accents (ACCENT) can effectively mitigate language mismatch effects
- The ACCENT method is promising for multilingual and low-resource language scenarios.
BibTex
@article{QuantifyingLanguageMismatch2024,
title={Towards Quantifying and Reducing Language Mismatch Effects in Cross-Lingual Speech Anti-Spoofing},
author={Tianchi Liu and Ivan Kukanov and Zihan Pan and Qiongqiong Wang and Hardik B. Sailor and Kong Aik Lee},
year={2024},
eprint={2409.08346},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2409.08346}
}